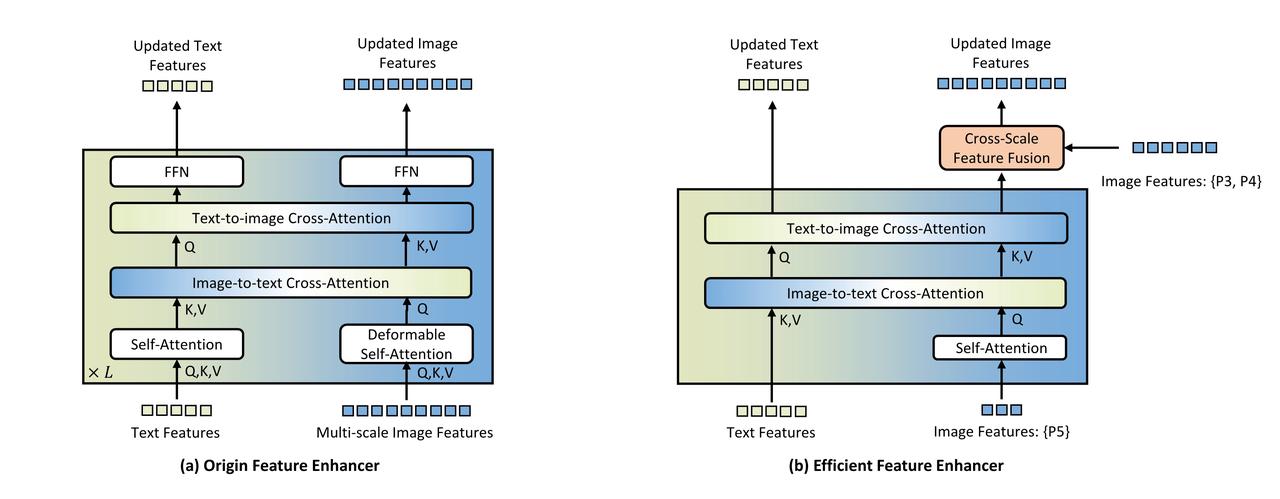
We introduce Grounding DINO 1.5 Edge, which is our most efficient, edge-optimized open-set object detection model. We replace the original feature enhancer with our newly proposed efficient one and employ EfficientViT-L1 as the image backbone for rapid multi-scale feature extraction. In our efficient feature enhancer, we limit cross-modality fusion to high-level image features (P5 level) only and introduce a cross-scale feature fusion module to integrate low-level image feature(P3, P4). This approach balances feature enhancement with computational efficiency.
State-of-the-art Zero-Shot Performance
After pre-training on Grounding-20M, we directly evaluate Grounding DINO 1.5 Edge on the COCO dataset and LVIS dataset in a zero-shot manner. The main results are shown in Table 1. Speed measurement is performed on the A100 GPU, expressed in frames per second (FPS). The format used is PyTorch speed / TensorRT FP32 speed, and FPS on NVIDIA Orin NX also reported. †indicates results of YOLO-World are reproduced by the latest official codes. ‡ indicates it used language cache, which did not calculate the latency of text encoder.

Compared with current real-time open-set detectors in an end-to-end test setting, which do not use language cache, Grounding DINO 1.5 Edge achieved a zero-shot AP of 45.0 on COCO. Regarding the zero-shot performance on LVIS-minival, Grounding DINO 1.5 Edge achieves remarkable performance, an AP score of 36.2, which surpasses all other state-of-the-art algorithms (OmDet-Turbo-T 30.3 AP, YOLO-Worldv2-L 32.9 AP, YOLO-Worldv2-M 30.0 AP, YOLO-Worldv2-S 22.7 AP). Notably, deploying Grounding DINO 1.5 Edge model optimized with TensorRT on NVIDIA Orin NX achieves an inference speed of over 10 FPS at an input size of 640x640.
Acknowledgment
We would like to thank everyone involved in the Grounding DINO 1.5 project, including application lead Wei Liu, product manager Qin Liu and Xiaohui Wang, front-end developers Yuanhao Zhu, Ce Feng, and Jiongrong Fan, back-end developers Weiqiang Hu and Zhiqiang Li, UX designer Xinyi Ruan, tester Yinuo Chen, and Zijun Deng for helping with demo videos.