Today, as intelligent applications have long been woven into the fabric of users' daily lives, downloading a counting app is simply a breeze. Counting applications have established a mature product and technology system — from the simple counting tools built into mobile phones to intelligent counters integrated with basic visual recognition, their technical frameworks are becoming increasingly sophisticated.
However, if we delve into the detailed scenarios of production and daily life, we will find that the counting needs that are truly effectively covered are still far from meeting the actual requirements — the core "counting capability" itself remains in the early stage of development.
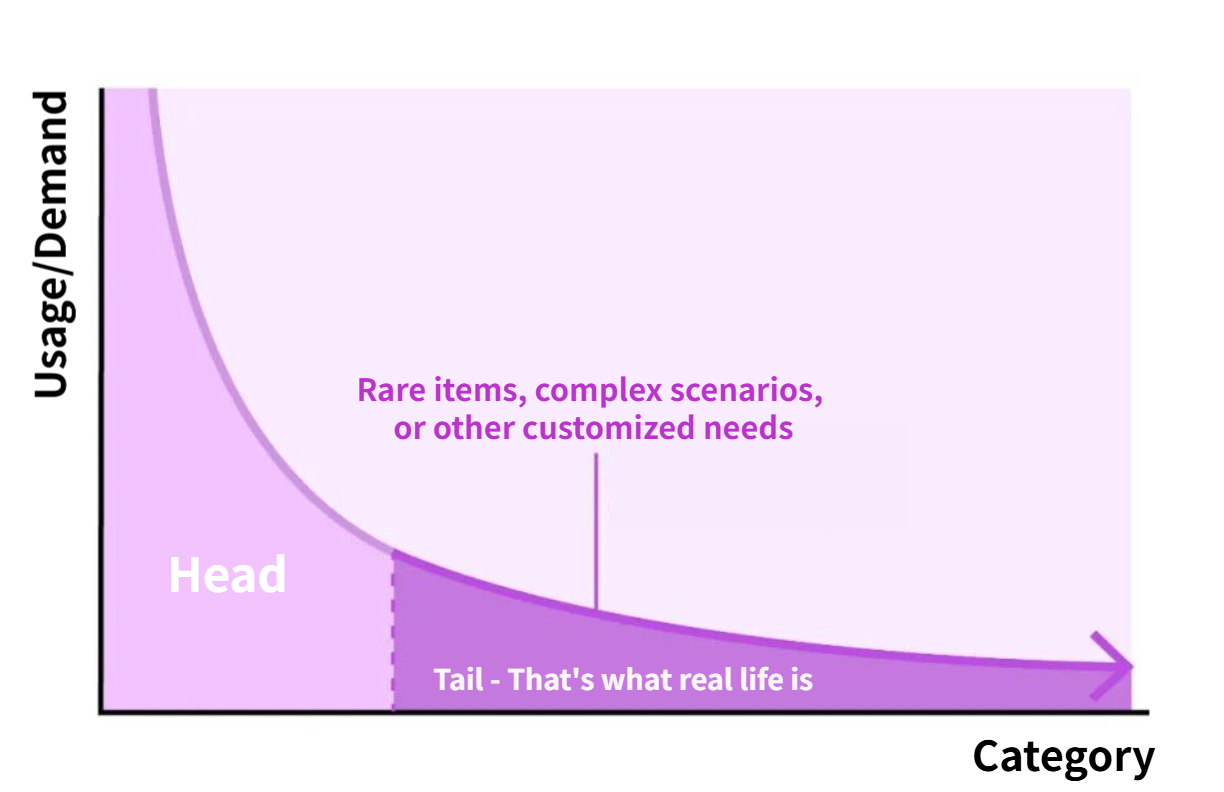
Figure 1: Long-Tail Theory in Counting Scenarios
Physical counting scenarios in the real world often exhibit fragmented and vertical characteristics, and consist of a large number of long-tailed scenarios — ranging from small-scale tasks such as restaurants counting the number of bowls and cups, laboratories counting bacterial colonies in petri dishes, to large-scale ones like factories verifying the inventory of bolts and orchards estimating the number of grape clusters. To this day, traditional counting applications are still far from being able to adapt to these vertical needs. The key to the problem is not the insufficient design of application functions, but the two insurmountable limitations of the vision models they rely on:
1. "Capability Bias" of General Vision Models: Inability to Recognize Long-Tailed Scenarios
While the general vision models integrated into traditional counting applications — whether closed-set models or open-set models designed to cover broader open-world scenarios — boast substantial knowledge reserves, this prior knowledge also leads these models to develop a pronounced "capability bias."
The rationale behind this lies in the following: For general scenarios (e.g., people, vehicles, animals, fruits, vegetables, and other common objects), vast volumes of annotated data are readily available, enabling the models to learn stable features from massive sample sets. In contrast, long-tailed scenarios or rare items (such as customized components, patterns on ancient artifacts, and specific insect species targeted for recognition) are highly niche, with extremely limited real-world data. Consequently, the models lack adequate learning resources, hindering their ability to develop precise recognition capabilities.

Figure 2: DINO-X Custom Templates Accurately Recognizing Lacewings
This "capability bias" brings two major problems in counting applications:
(1) Insufficient Flexibility
To enable a vision model to accurately recognize new items, it is necessary to re-collect annotated data and invest computing power for full-scale training. For the countless long-tailed scenarios, this process is cumbersome and time-consuming.
(2) High Customization Cost and Low Cost-Effectiveness
If an enterprise wants to customize a counting solution for a certain type of niche item, it not only has to bear additional technical costs for data collection and model training, but may also fall into a triple dilemma in terms of business model:
a) If this function is provided separately as a retail package, it may even be difficult to recover the cost, resulting in a mismatch between input and output;
b) If the R&D costs are allocated to mass services, it will increase the cost for most users who do not have this demand, which may lead to user churn;
c) If this cost is entirely borne by the user who proposes customization, small and medium-sized businesses or individual users will find it difficult to afford.

Figure 3: The Triple Dilemma for Enterprises in Providing Customized Counting Solutions
In the end, a large number of personalized counting needs can only be met by choosing manual counting as a second-best option, and then relying on subsequent review processes to ensure accuracy. This method is not only inefficient, but also prone to frequent errors.
2. Pre-Trained Small Models: Inability to Cover "Niche Needs"
To make up for the shortcomings of general vision models, suppliers of counting applications have proposed another solution: providing users with a large number of pre-trained small models, packaged as template solutions. Users can select corresponding or similar templates according to their own needs to complete counting. These small models have been specially optimized for common segmented scenarios in industry and daily life (such as counting steel pipes at construction sites, counting pills in pharmacies, counting pearls in markets, etc.), and perform more accurately in specific scenarios.

Figure 4: Common Counting Scenarios
Pre-trained small models have indeed greatly improved the user experience: on the one hand, the accuracy of counting results in common scenarios has been significantly improved; on the other hand, users do not need to wait for the model to be trained from scratch. At least, they can find scenarios similar to their current needs among many small models, and compared with the vague recognition of long-tailed scenarios by general models, the counting performance of vertical small models has also been significantly improved.
However, the coverage of pre-trained small models is always limited: service providers have neither the motivation nor the ability to cover all scenarios — for needs that are extremely niche or even never encountered before, such as "counting electronic components of special models" and "counting the leaves of a certain type of endangered plant", the input of time/cost for pre-training exclusive small models is completely out of proportion to the return.
From the user's perspective, the purchasers of pre-trained small models are mostly enterprises. Compared with re-customizing vision models, the cost is lower and the performance is better; but for start-up teams or individual users with limited budgets, this cost is still not low — more importantly, pre-training small models for rare items still requires users to provide a large number of image data, which is cumbersome and time-consuming. Even if there are relevant tools on the market that allow users to train models by themselves, most individual users lack AI engineering experience. Faced with professional operations such as data annotation and model parameter tuning, they can only eventually be deterred.
Breaking the "Stagnation Curse" of Vision Models
Currently, counting applications are deeply trapped in the development dilemma, which essentially stems from the general stagnation of vision models in the field of "personalized scenarios + rare items". This stagnation has formed an insurmountable negative cycle: on the one hand, users are unwilling to bear the high cost and high-threshold model training for niche needs, resulting in the difficulty in generating scarce data in new scenarios; on the other hand, researchers cannot optimize the model capabilities in a targeted manner due to the lack of key data support. Eventually, a deadlock of "needs exist objectively but cannot be met" is formed.
To solve this problem, DINO-X has proposed a "custom template" solution. The core of the solution is to decompose the core demand of "custom model capability" into two modules: "basic model capability + exclusive visual features". On the premise of fully retaining the performance of the original DINO-X model, this solution greatly reduces the user's customization threshold — users do not need to train the model from scratch and at the same time have the powerful inference performance of DINO-X. On this basis, users only need to provide a small number of annotated samples (usually a few pictures are enough) to quickly generate a visual feature template for specific items, avoiding the complex training process and heavy development costs.
In addition, the threshold for creating custom templates is extremely low. Users do not need to master AI expertise and can complete all operations through the automated tools provided by the platform, truly realizing personalized customization with zero technical threshold.
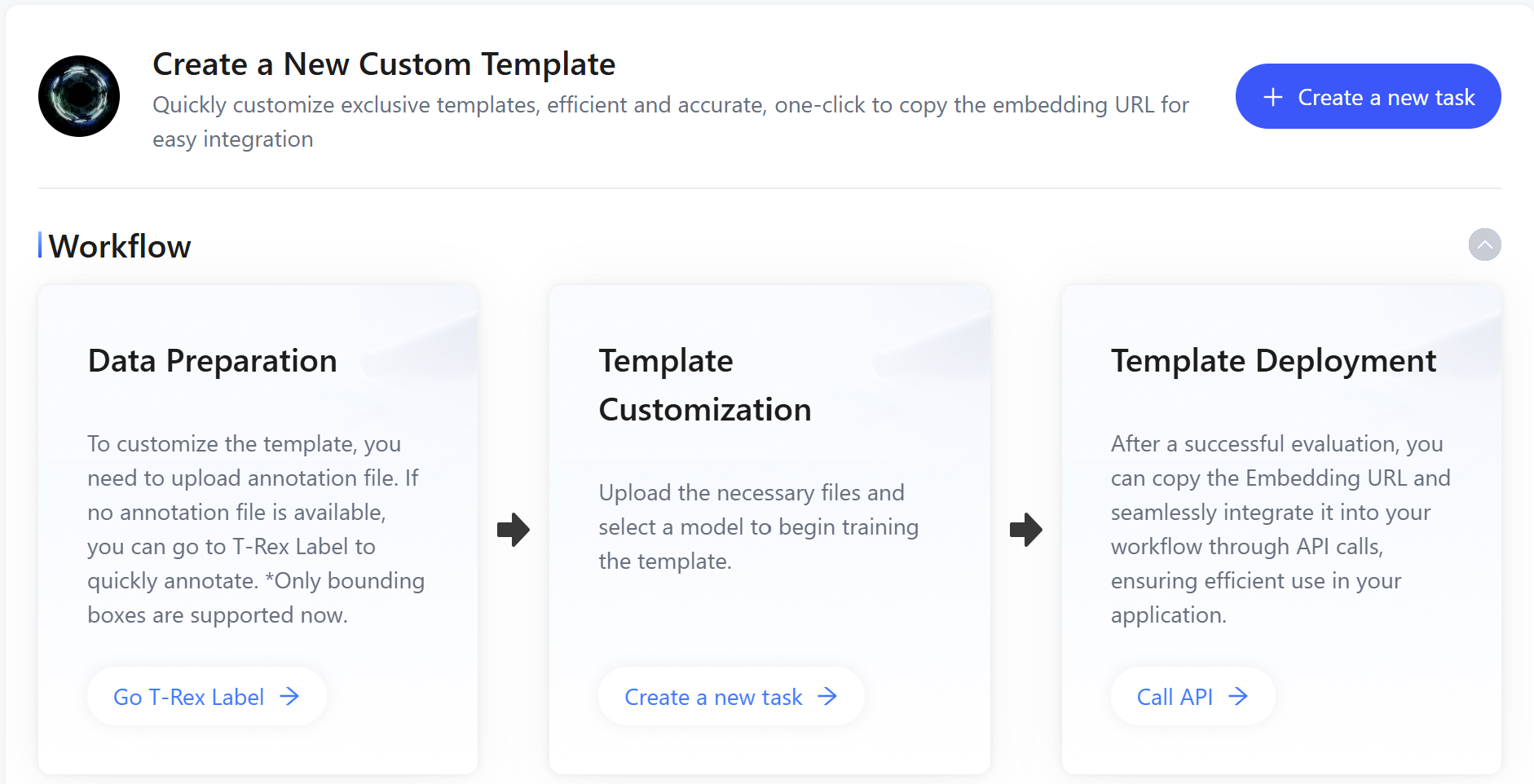
Figure 5: Customize Your Exclusive DINO-X Visual Template in Just 3 Steps
By solving the long-tailed recognition problem of vision models, the dilemma of counting scenarios can be easily resolved. Through connecting its intelligent counting software CountAnything, the DINO-X Platform has built a complete process of "long-tailed template training -> mobile counting solution implementation", providing users with a smoother experience: users with long-tailed counting needs can either independently train exclusive visual templates and load them into CountAnything to achieve personalized counting; or submit a small number of image samples to apply for the official team's (limited-time) free assistance in training custom templates, and complete the adaptation with CountAnything, truly realizing "efficient and low-cost counting solution customization".
It can be said that the revolution of DINO-X custom templates to counting applications is not only an upgrade of capabilities at the technical level, but also a redefinition of counting needs — it transforms counting from "standardized services for general scenarios" to "personalized satisfaction for long-tailed scenarios", and ultimately promotes intelligent counting to truly penetrate into every vertical field of life, industry, science and other industries.
Reference Resources
1.CountAnything, an AI Intelligent Counting App : https://deepdataspace.com/products/countanything
2.DINO-X Template Market: https://cloud.deepdataspace.com/custom/market
3.Customize Exclusive Visual Templates on DINO-X Platform: https://cloud.deepdataspace.com/custom/template