We present DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. We develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. We have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. We also extend DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. DINO-X encompasses two models:
-
DINO-X Pro: the most capable model with enhanced perception capabilities for various scenarios
-
DINO-X Edge: our efficient model optimized for faster inference speed and better suited for deployment on edge devices.

Model Architecture
DINO-X Overall Framework
We present the overall framework of DINO-X in the following image: DINO-X can accept text prompts, visual prompts, and customized prompts as input, and it can generate representations at various semantic levels, including bounding boxes, segmentation masks, pose keypoints, and object captions.

DINO-X Language Head Design
We present the detailed design of the language head in DINO-X in Figure 3. It involves using a frozen DINO-X to extract object tokens, and a linear projection aligns its dimensions with the text embeddings. The lightweight language decoder then integrates these object and task tokens to generate response outputs in an autoregressive manner. The task tokens equip the language decoder with the capability of tackling different tasks.

Data Construction and Model Training
Data Collection
To ensure the core open-vocabulary object detection capability, we developed a high-quality and semantic-rich grounding dataset, which consists of over 100 million images collected from the web, termed Grounding-100M. We used the training data from T-Rex2 with some additional industrial scenario data for visual prompt-based grounding pre-training. We used open-source segmentation models, such as SAM and SAM2, to generate pseudo mask annotations for a portion of the Grounding-100M dataset, which serves as the main training data for our mask head. And we sampled a subset of high-quality data from the Grounding-100M dataset and utilized their box annotations as our prompt-free detection training data. We also collected over 10 million region understanding data, covering object recognition, region captioning, OCR, and region-level QA scenarios for language head training.
Model Training
To overcome the challenge of training multiple vision tasks, we adopt a two-stage strategy. In the first stage, we conducted joint training for text-prompt-based detection, visual-prompt-based detection, and object segmentation.Such a large-scale grounding pre-training ensures an outstanding open-vocabulary grounding performance of DINO-X and results in a foundational object-level representation. In the second stage, we froze the DINO-X backbone and added two keypoint heads (for person and hand) and a language head, each being trained separately. By adding more heads, we greatly expand DINO-X's ability to perform more fine-grained perception and understanding tasks, such as pose estimation, region captioning, object-based QA, etc. Subsequently, we leveraged prompt-tuning techniques and trained a universal object prompt, allowing for prompt-free any-object detection while preserving the model's other capabilities. Such a two-stage training approach has several advantages: (1) it ensures that the model's core grounding capability is not affected by introducing new abilities, and (2) it also validates that large-scale grounding pre-training can serve as a robust foundation for an object-centric model, allowing for seamless transfer to other open-world understanding tasks.
Model Evaluation
We evaluation our DINO-X model across different perception benchmarks in this section, including detection, segmentation, pose estimation, object-level understanding, etc.
DINO-X Pro
Evaluation on Zero-Shot Object Detection and Segmentation Benchmarks
DINO-X shows a significant performance improvement compared to previous state-of-the-art methods. As shown in Table 1, DINO-X achieves 56.0 box AP on COCO detection benchmark.On the LVIS-minival and LVIS-val benchmarks, DINO-X Pro achieves 59.8 box AP and 52.4 box AP, respectively, surpassing the previously best-performing Grounding DINO 1.6 Pro model by 2.0 AP and 1.1 AP, respectively. Notably, for the detection performance on LVIS rare classes, DINO-X achieves 63.3 AP on LVIS-minival and 56.5 AP on LVIS-val, significantly surpassing the previous SOTA Grounding DINO 1.6 Pro model by 5.8 AP and 5.0 AP, respectively, demonstrating the exceptional capability of DINO-X in long-tailed object detection scenarios.


Evaluation on Visual-Prompt Based Detection Benchmarks
To assess the visual prompt object detection capability of DINO-X, we conduct experiments on the few-shot object counting benchmarks.As shown in the following table, compared with its related works, including T-Rex, T-Rex2, etc., DINO-X achieves state-of-the-art performance, demonstrating its strong capability in practical visual prompt object detection.

Evaluation on Human 2D Keypoint Benchmarks
As we froze the backbone of DINO-X and trained only the pose head, the evaluation on object detection and segmentation still follows the zero-shot setting.As shown in Table 3, through training the pose head on multiple pose datasets, our model can effectively predicts keypoints across various person styles, including everyday scenarios, crowded environments, occlusions, and artistic representations. While our model achieves an AP that is 1.6 lower than ED-Pose (primarily due to the limited number of trainable parameters in the pose head), it outperforms existing models on CrowdPose and Human-Art by 3.4 AP and 1.8 AP, respectively, showing its remarkable generalization ability on more diverse scenarios.

Evaluation on Human Hand 2D Keypoint Benchmarks
In addition to evaluating human pose, we also present hand pose results on the HInt benchmark. As shown in Table 4, DINO-X achieves the best performance on the PCK@0.05 metrics, indicating its strong capability on highly accurate hand pose estimation.

Evaluation on Object Recognition
We verify the effectiveness of our language head with related works on object recognition benchmarks, which need to recognize the category of the object in a speciffed region of an image. As shown in Table 5, Our model achieves 71.25% in SS and 41.15% in S-IoU, surpassing Osprey by 6.01% in SS and 2.06% in S-IoU on the LVIS-val dataset. On the PACO dataset, our model is inferior to Osprey. Note that we did not include LVIS and PACO in our langauge head training and the performance of our model is achieved in a zero-shot manner. The lower performance on PACO might be due to the discrepancy between our training data and PACO. And our model only has 1% trainable parameters compared with Osprey.

Evaluation on Region Captioning
We evaluate our model’s region caption quality on Visual Genome and RefCOCOg. The evaluation results are presented in Table 6. Remarkably, based on object-level features extracted by a frozen DINO-X backbone and without utilizing any Visual Genome training data, our model achieves a 142.1 CIDEr score on the Visual Genome benchmark in a zero-shot manner. Further, after ffne-tuning on Visual Genome dataset, we set a new state-of-the-art result with 201.8 CIDEr score with only a light-weight language head.

DINO-X Edge
DINO-X Edge builds upon Grounding DINO 1.5 Edge by using EfficientViT for efficient feature extraction and a Transformer encoder-decoder architecture. It introduces some key improvements to enhance performance and efficiency:
- A stronger text prompt encoder, based on the CLIP model, improves region-level multi-modal alignment without affecting inference speed.
- Knowledge distillation from the Pro model, using feature-based and response-based techniques, boosts zero-shot capabilities.
- Improved FP16 inference with optimized normalization increases speed to 20.1 FPS, marking significant improvements over its predecessors.
Evaluation on Zero-Shot Object Detection Benchmarks
DINO-X Edge demonstrates strong zero-shot object detection capabilities, achieving significant performance improvements on the COCO and LVIS benchmarks after pre-training on Grounding-100M. It surpasses existing real-time open-set detectors on COCO and achieves impressive results of 48.3 AP on LVIS-minival and 42.0 AP on LVIS-val, excelling in long-tailed detection scenarios. Evaluated on NVIDIA Orin NX and A100 GPUs, DINO-X Edge benefits from FP16 quantization, maintaining accuracy while increasing inference speed by 33%, reaching 20.1 FPS with an input size of 640×640, compared to 15.1 FPS from its predecessor, Grounding DINO 1.6 Edge.

Case Analysis and Qualitative Visualization
In this section, we visualize the different capabilities of DINO-X models across various real-world scenarios. The images are primarily sourced from COCO, LVIS, V3Det, SA-1B, and other publicly available resources. We are deeply grateful for their contributions, which have significantly benefited the community.
Open-World Object Detection
As illustrated in Figure 5, DINO-X demonstrates the capability to detect any objects based on the given text prompt. It can identify a wide range of objects, from common categories to long-tailed classes and dense object scenarios, showcasing its robust open-world object detection capabilities.

Long Caption Phrase Grounding
As illustrated in Figure 6, DINO-X exhibits an impressive ability to locate corresponding regions in an image based on noun phrases from a long caption. The capability of mapping each noun phrase in a detailed caption to specific objects in an image marks a significant advancement in deep image understanding. This feature has substantial practical value, such as enabling multimodal large language models (MLLMs) to generate more accurate and reliable responses.

Open-World Object Segmentation and Visual Prompt Counting
As shown in Figure 7, beyond Grounding DINO 1.5, DINO-X not only enables open-world object detection based on text prompts but also generates the corresponding segmentation mask for each object, providing richer semantic outputs. Furthermore, DINO-X also supports detection based on user-defined visual prompts by drawing bounding boxes or points on target objects. This capability demonstrates exceptional usability in object counting scenarios.
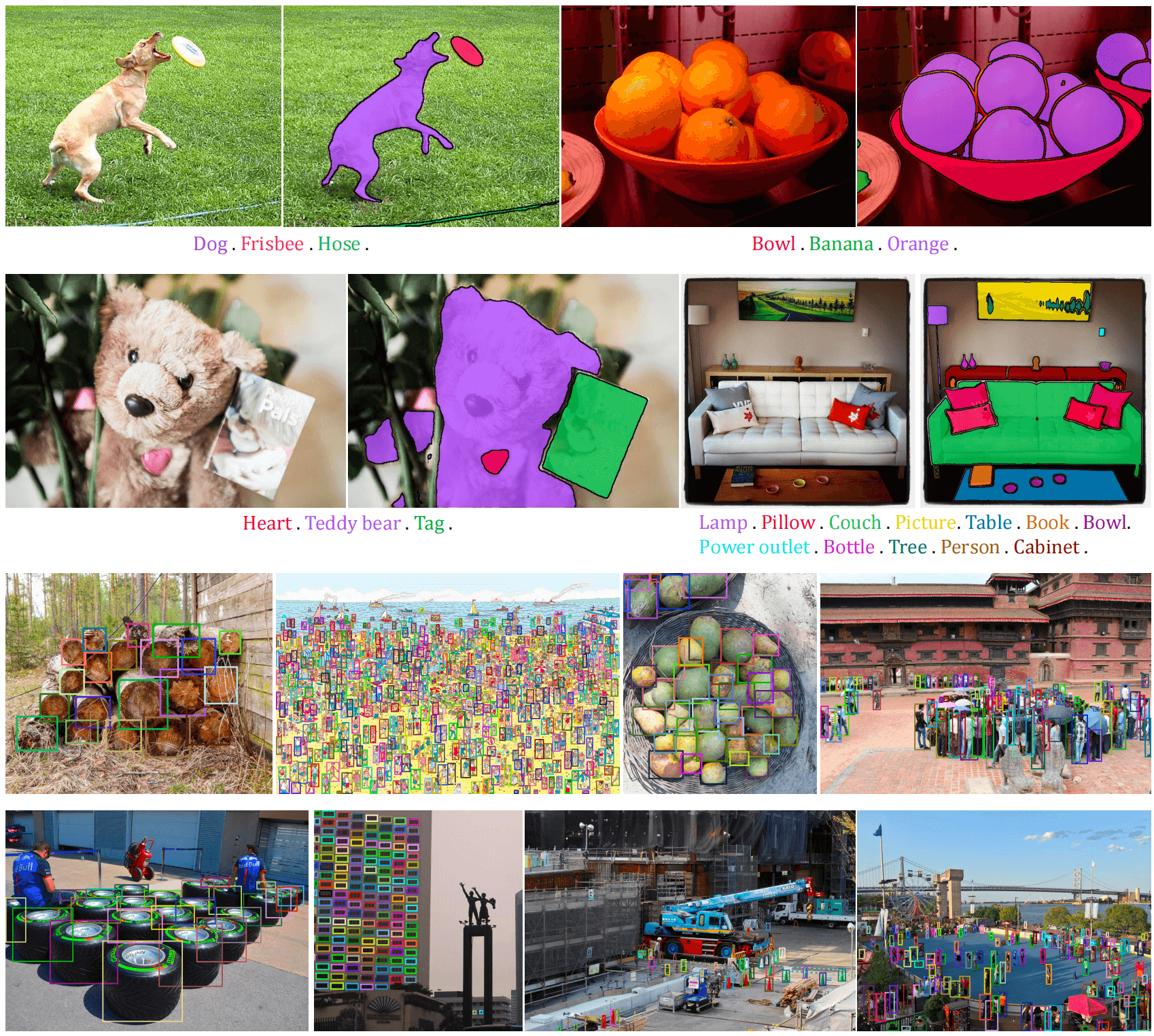
Prompt-Free Object Detection and Recognition
In DINO-X, we developed a highly practical feature named prompt-free object detection, which allows users to detect any objects in an input image without providing any prompts. As shown in Figure 8 When combined with DINO-X's language head, this feature enables seamless detection and identification of all objects in the image without requiring any user input.

Dense Region Caption
As illustrated in Figure 9, DINO-X can generate more fine-grained captions for any specified region. Furthermore, with DINO-X's language head, we can also perform tasks such as region-based QA and other region understanding tasks. Currently, this feature is still in the development stage and will be released in our next version.

Human Body and Hand Pose Estimation
As shown in Figure 10, DINO-X can predict keypoints for specific categories through the keypoint heads based on the text prompts. Trained on a combination of COCO, CrowdHuman, and Human-Art datasets, DINO-X is capable of predicting human body and hand keypoints across various scenarios.

Conclusion
We introduce DINO-X, a strong object-centric vision model to advance the field of open-set object detection and understanding. The flagship model, DINO-X Pro, has established new records on the COCO and LVIS zero-shot benchmarks, showing a remarkable improvement in detection accuracy and reliability. To make long-tailed object detection easy, DINO-X not only supports open-world detection based on text prompts but also enables object detection with visual prompts and customized prompts for customized scenarios. Moreover, DINO-X extends its capabilities from detection to a broader range of perception tasks, including segmentation, pose estimation, and object-level understanding tasks. To enable real-time object detection for more applications on edge devices, we also developed the DINO-X Edge model, which further expands the practical utility of the DINO-X series models.
Contributions and Acknowledgments
We would like to express our gratitude to everyone involved in the DINO-X project. The contributions are as follows (in no particular order):
- DINO-X Pro: Yihao Chen, Tianhe Ren, Qing Jiang, Zhaoyang Zeng, and Yuda Xiong.
- Mask Head: Tianhe Ren, Hao Zhang, Feng Li, and Zhaoyang Zeng.
- Visual Prompt and Prompt-Free Detection: Qing Jiang.
- Pose Head: Xiaoke Jiang, Xingyu Chen, Zhuheng Song, and Yuhong Zhang.
- Language Head: Wenlong Liu, Zhengyu Ma, Junyi Shen, Yuan Gao, and Yuda Xiong.
- DINO-X Edge: Hongjie Huang, Han Gao, and Qing Jiang.
- Grounding-100M: Yuda Xiong, Yihao Chen, Tianhe Ren, Qing Jiang, Zhaoyang Zeng, and Shilong Liu.
- Language Head and DINO-X Edge Lead: Kent Yu.
- Overall Project Lead: Lei Zhang.
We would also like to thank everyone involved in the DINO-X playground and API support, including application lead Wei Liu, product manager Qin Liu and Xiaohui Wang, front-end developers Yuanhao Zhu, Ce Feng, and Jiongrong Fan, back-end developers Zhiqiang Li and Jiawei Shi, UX designer Zijun Deng, operation intern Weijian Zeng, tester Jiangyan Wang, and Peng Xiao for providing suggestions and feedbacks on customized scenarios.