Today, we introduce Grounding DINO 1.6 Series, which improves upon Grounding DINO 1.5 in the following aspects:
- Grounding DINO 1.6 Pro: Grounding DINO 1.6 Pro utilizes a larger-scale higher-quality training dataset (Grounding-30M), establishing new SOTA results on zero-shot transfer benchmarks: 55.4 AP on COCO , 57.7 AP on LVIS-minival, and 51.1 AP on LVIS-val. Moreover, it demonstrates significantly superior performance compared with the 1.5 Pro model in several specific detection scenarios, such as animal detection, text detection, etc.
- Grounding DINO 1.6 Edge: Grounding DINO 1.6 Edge further optimizes the model architecture for edge devices. It not only improves the inference speed (at an input size of 800 × 800) to 14 FPS, a 40% increase compared with the 1.5 Edge model, but also delivers superior performance on zero-shot transfer benchmarks: 44.8 AP on COCO, 34.6 AP on LVIS-minival, and 31.0 AP on LVIS-val.
- Prompt Tuning for Customized Detection Scenarios: Supervised prompt tuning is implemented to demonstrate the superiority of Grounding DINO 1.6 when customizing to long-tailed detection problems, where only a few labeled images are available. Prompt tuning with Grounding DINO 1.6 achieves remarkably better performance compared with YOLOv8 under the same setting, showcasing its great potential in many practical applications.
Grounding DINO 1.6 Pro
More Training Data with Better Quality
We further collected and annotated additional data based on the Grounding-20M dataset, expanding it to a 30M Grounding dataset, termed Grounding-30M, and enhancing the data quality.
Stronger Zero-Shot Performance on Public Benchmarks
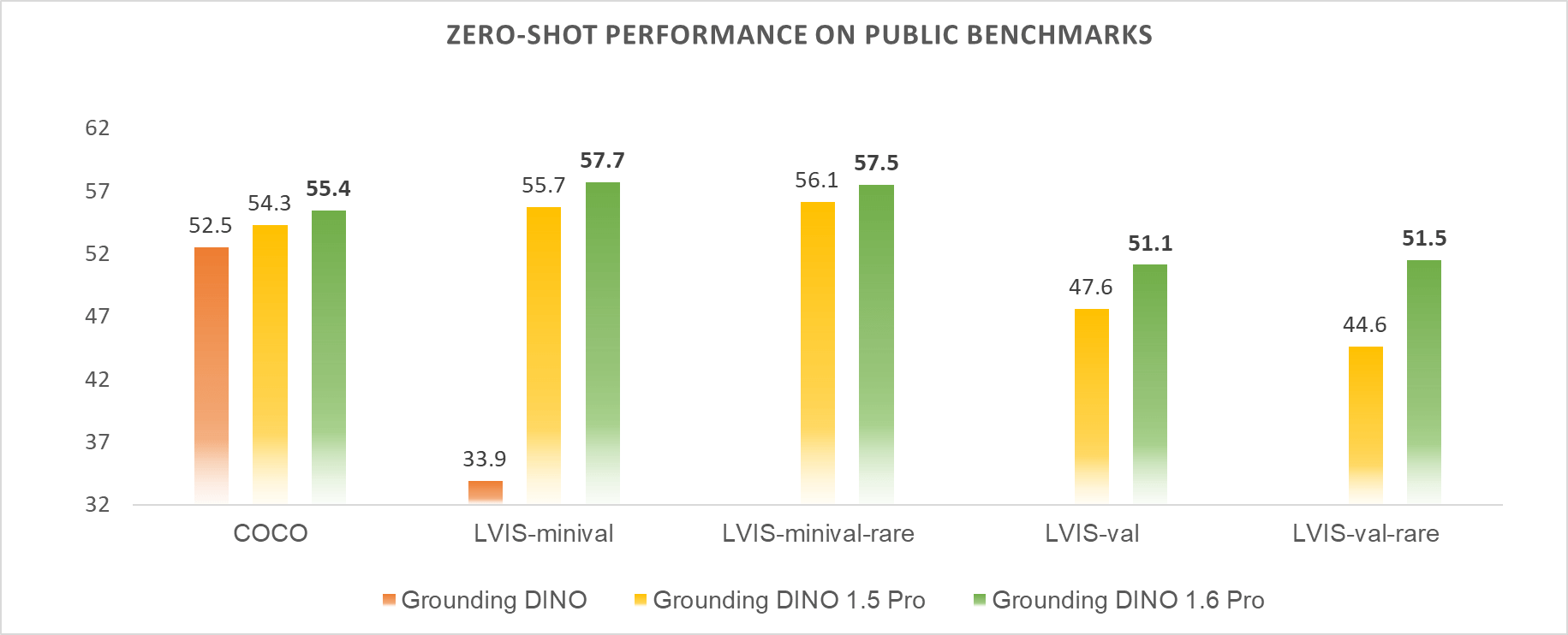
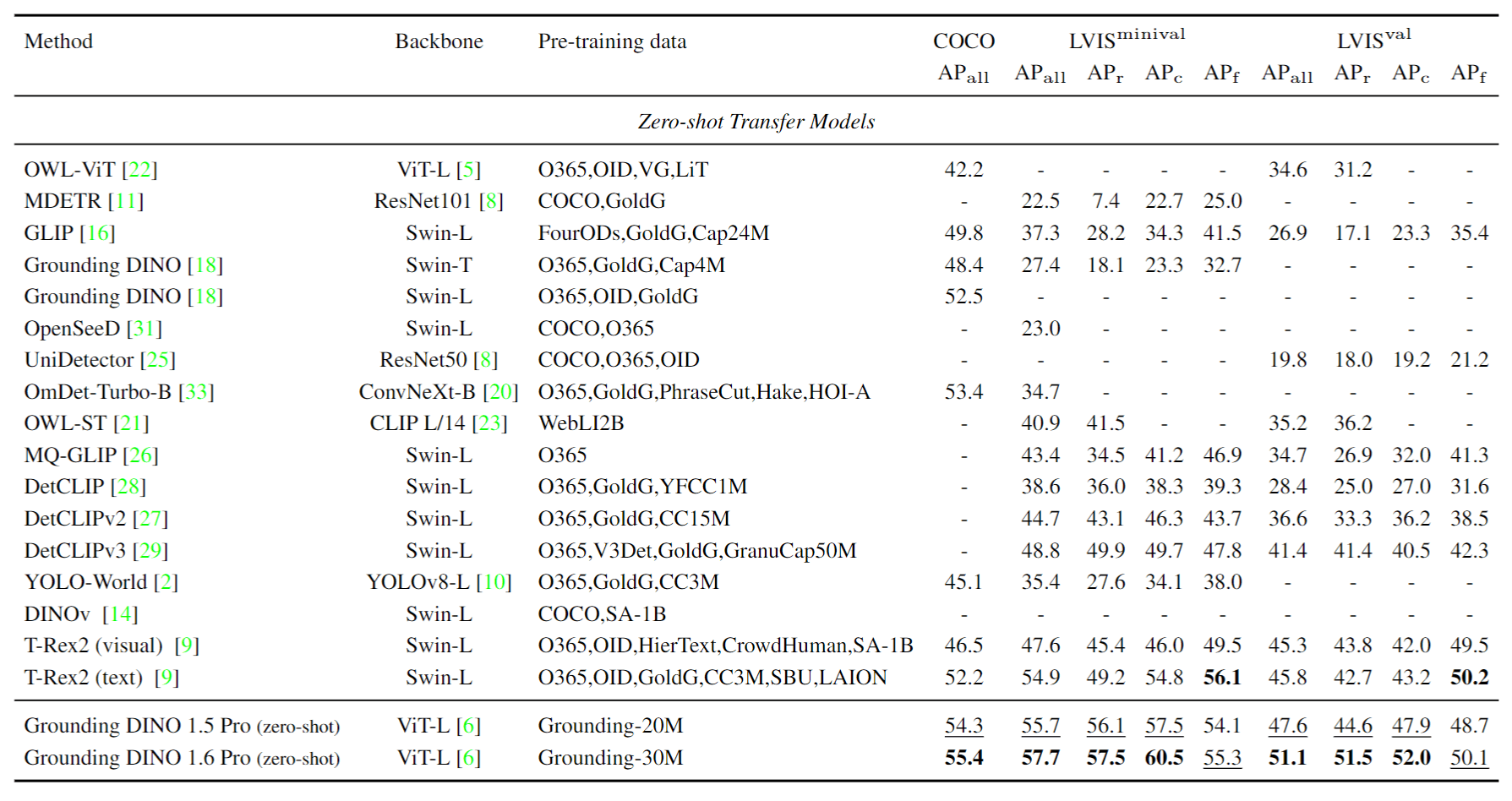
Grounding DINO 1.6 achieves better zero-shot transfer performance on public benchmarks. As illustrated in Figure 1, Grounding DINO 1.6 achieves 55.4 AP, 57.7 AP, and 51.5 AP on the COCO, LVIS-minival split, and LVIS-val benchmarks. Compared with Grounding DINO 1.5 Pro, these results represent improvements of +1.1, +2.0, and +3.5 AP on COCO, LVIS-minival, and LVIS-val, respectively. Moreover, it exhibits significant performance improvements in the rare classes of the LVIS-val benchmark. The comprehensive performance results are presented in Table 1.
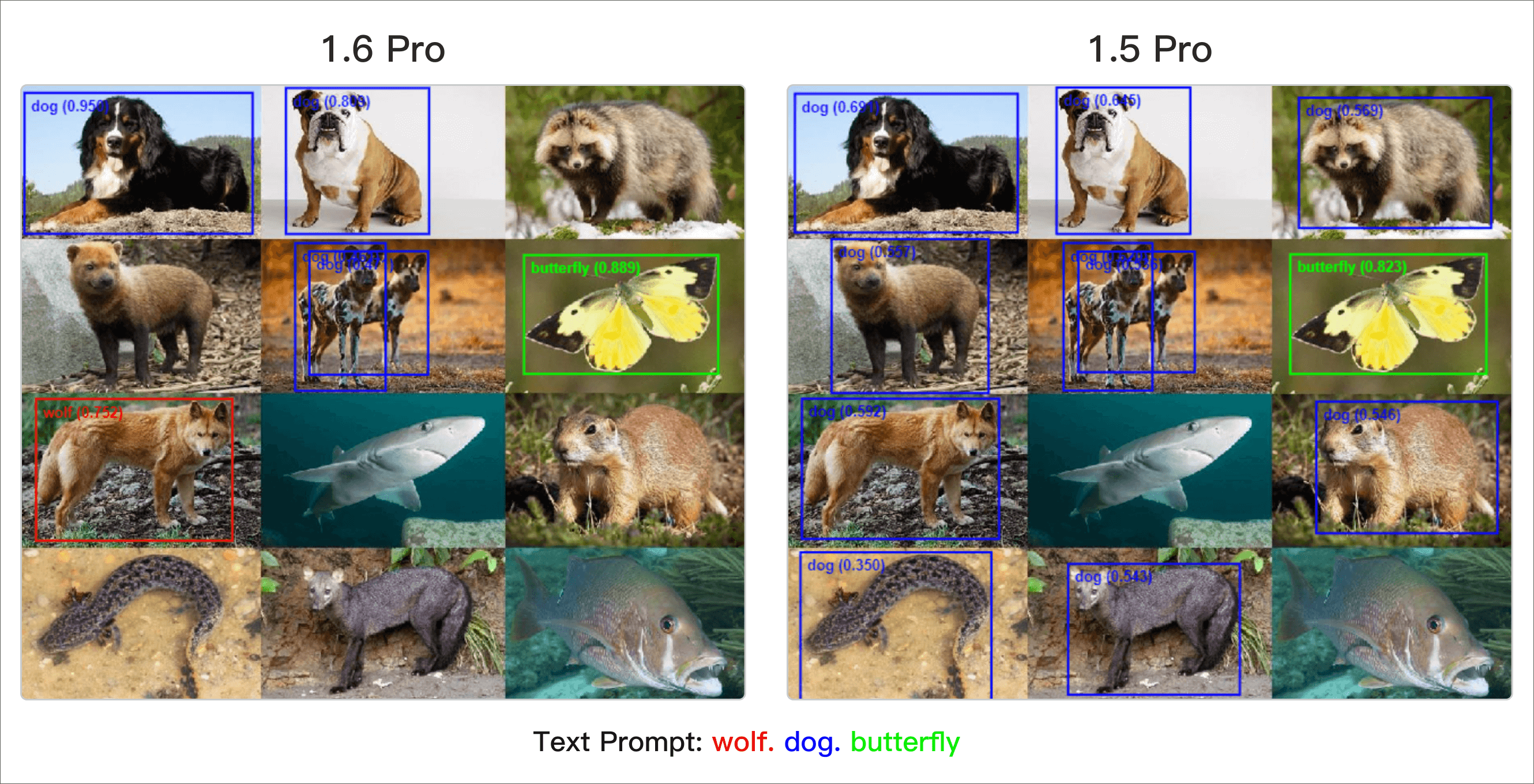
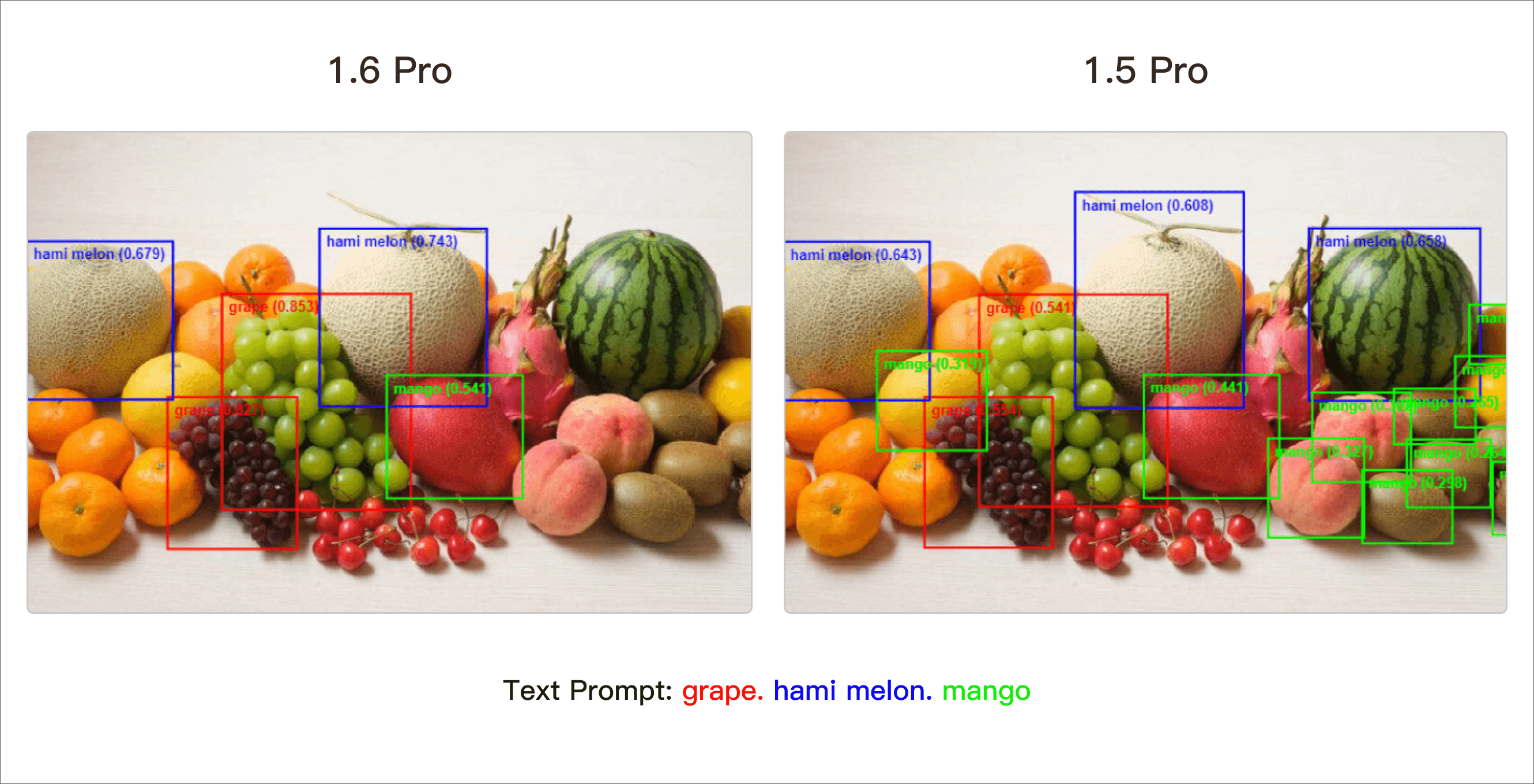
Enhancing the Model's Detection Capability on Specific Scenarios
Compared with Grounding DINO 1.5 Pro, Grounding DINO 1.6 Pro demonstrates superior model performance on specific scenarios such as animal detection, fruit detection, etc.




Grounding DINO 1.6 Edge
Grounding DINO 1.6 Edge adopts the same backbone and similar Transformer architectures as Grounding DINO 1.5 Edge. To further improve its performance and computational efficiency, we made the following modifications:
- Feature Utilization: We remove P3 and use only the P4, P5, and P6 features in the feature enhancer and decoder.
- Query Reduction: Given that in most real-world scenarios an image typically contains fewer than 300 objects, we reduce the number of queries from 900 to 300.
- Training Strategy: For faster convergence, we adopt a stronger denoising training strategy by increasing the DN number from 100 to 300.
We also added the FP16 inference capability on NVIDIA Orin NX for 1.6 Edge. With these modifications, Grounding DINO 1.6 Edge sets a new record on edge devices, achieving an inference speed of 14 FPS (with runtime visualization overhead) at input resolution 800x800 on Orin NX and better accuracies than its 1.5 Edge counterpart.
Stronger Zero-Shot Transfer Performance
After training on Grounding-30M, we directly evaluate Grounding DINO 1.6 Edge on the COCO and LVIS benchmarks in a zero-shot manner. The main results are presented in Table 2. Speed measurements were performed on both NVIDIA A100 and NVIDIA Orin NX, expressed in frames per second (FPS). The speeds of both the PyTorch model and the TensorRT model are reported. Additionally, the FPS of the TensorRT model on the NVIDIA Orin NX is also provided.
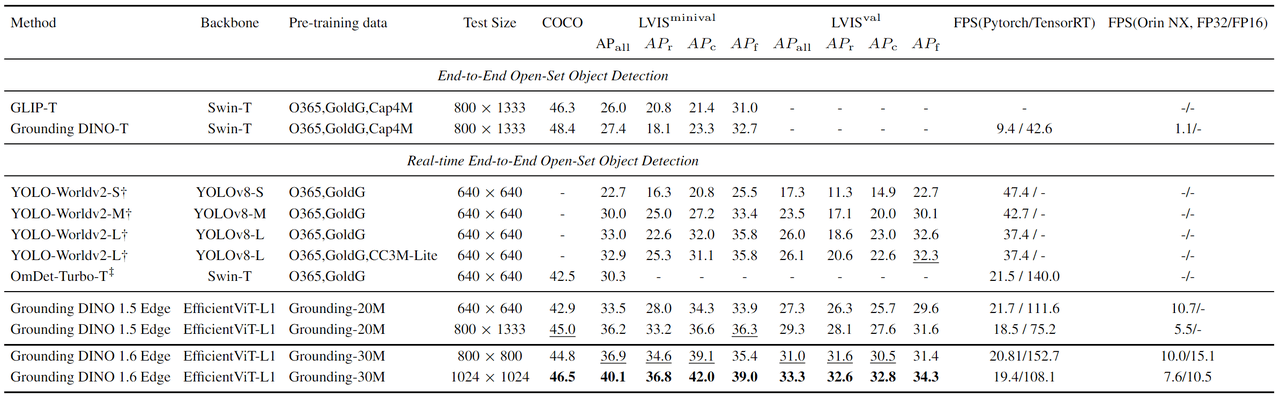
At the input resolution of 1024x1024, which has a similar number of input pixels compared with 800x1333, Grounding DINO 1.6 Edge achieves the best performance on the zero-shot transfer benchmarks on edge devices: 46.5 AP on COCO, 40.1 AP on LVIS-minival, and 33.3 AP on LVIS-val.
Thanks to the further optimized edge model architecture, we can increase the input resolution to 800x800, instead of using 640x640 as in 1.5 Edge. With the newly added FP16 inference capability, this setting leads to an inference speed of 15.1 FPS, which is 50% faster than 1.5 Edge (10.7 FPS) at input resolution 640x640, and meanwhile achieves better accuracies on COCO, LVIS-minimal, and LVIS-val.
Qualitative Visualization for Grounding DINO 1.6 Edge
SPT: Supervised Prompt Tuning
Grounding DINO enables open vocabulary detection by providing image and target object category name as prompt. However, two main challenges persist:
- How to detect target objects effectively without depending on standard category names, especially in industrial environments with specialized or uncommon product names.
- How to select the best prompt for a specific set of target objects to enhance detection accuracy, considering the ambiguity and vagueness of text.
These challenges are particularly relevant in industrial production and automation, where the product names are often unique or domain-specific, and achieving the highest possible detection accuracy is crucial for improving productivity and reducing manual labor.
To address these issues, we present the Supervised Prompt Tuning (SPT) method to customize "visual prompt." The idea is similar to supervised fine-tuning, but we only allow the prompt embeddings to be updated. Such an approach is particularly useful when only a few labeled images are available for model customization. The resulting optimized prompt embeddings can be paired with Grounding DINO and serve as the role of text prompt to indicate human intention on detection targets during the inference phase.
SPT Evaluation on Different Industry Scenarios and Varying Size of Traning Data
The fundamental concept of SPT is simple, yet its effectiveness is truly remarkable. We assessed SPT from two perspectives:
- its performance across diverse industry scenarios
- its performance with varying amounts of training data.
We conducted this evaluation based on the LVIS dataset, a widely recognized benchmark for object detection, especially for assessing long-tailed categories. Under the same dataset configurations, we compared the performance of SPT+GD1.6 (GD short for Grounding DINO), SPT+GD1.0, and YOLOv8, one of the most widely used model in industry.
LVIS Category Grouping with LLMs
The LVIS dataset includes over 1,200 subcategories, each with a descriptive text. We grouped these sub-categories into 12 industry-specific domain datasets with the assistance of LLM (large language model) classification and manual review.
- Classification by LLMs: We submitted each sub-category name and its description to GPT-3.5-turbo, GPT-4o, and Claude3.5, requesting them to categorize the sub-category under one or more industries.
- Manual Review: If the three LLMs provide inconsistent responses, we manually review the classification outcome.
We utilized the standard LVIS-minival dataset for performance evaluation, assessing it using the mAP0.5:0.95 metric. The 12 domain datasets are shown in Table 3.
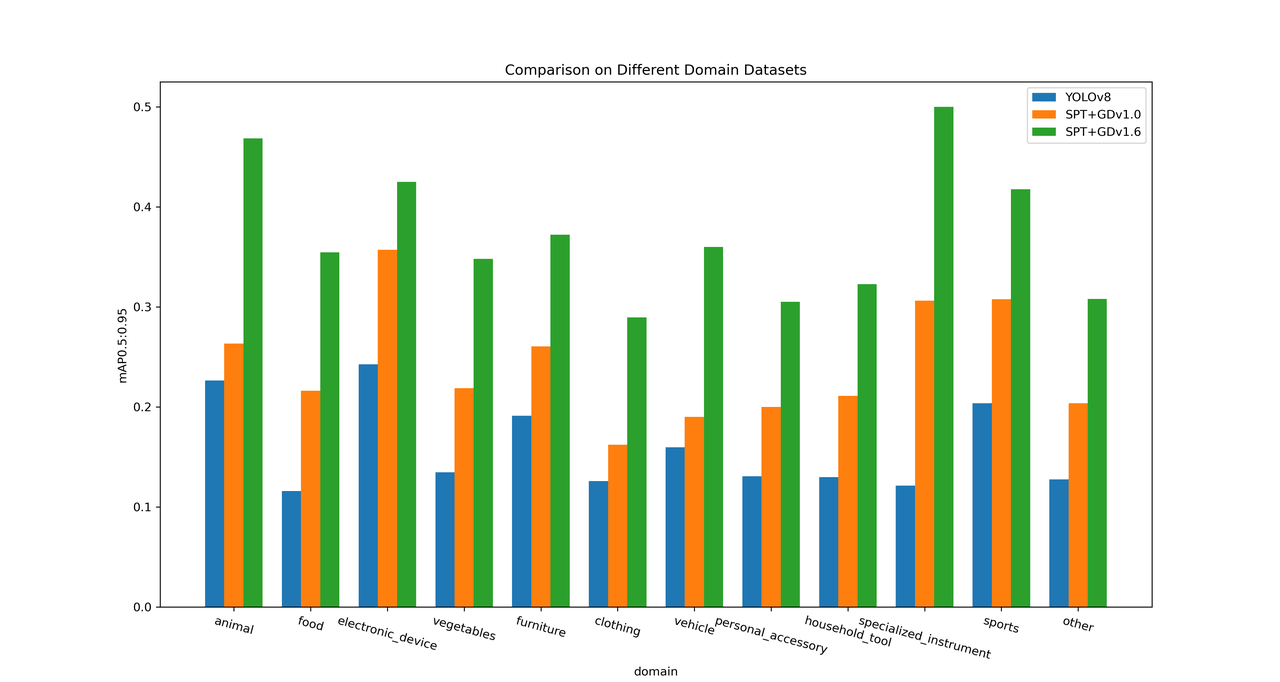
Performance across Different Industry Scenarios
The results shown in Figure 3 clearly advocate the advantages of SPT. The mAP of YOLOv8 is lower than SPT+GD1.0, which is in turn lower than SPT+GD1.6. This indicates the superior performance of SPT, especially across different industry scenarios.
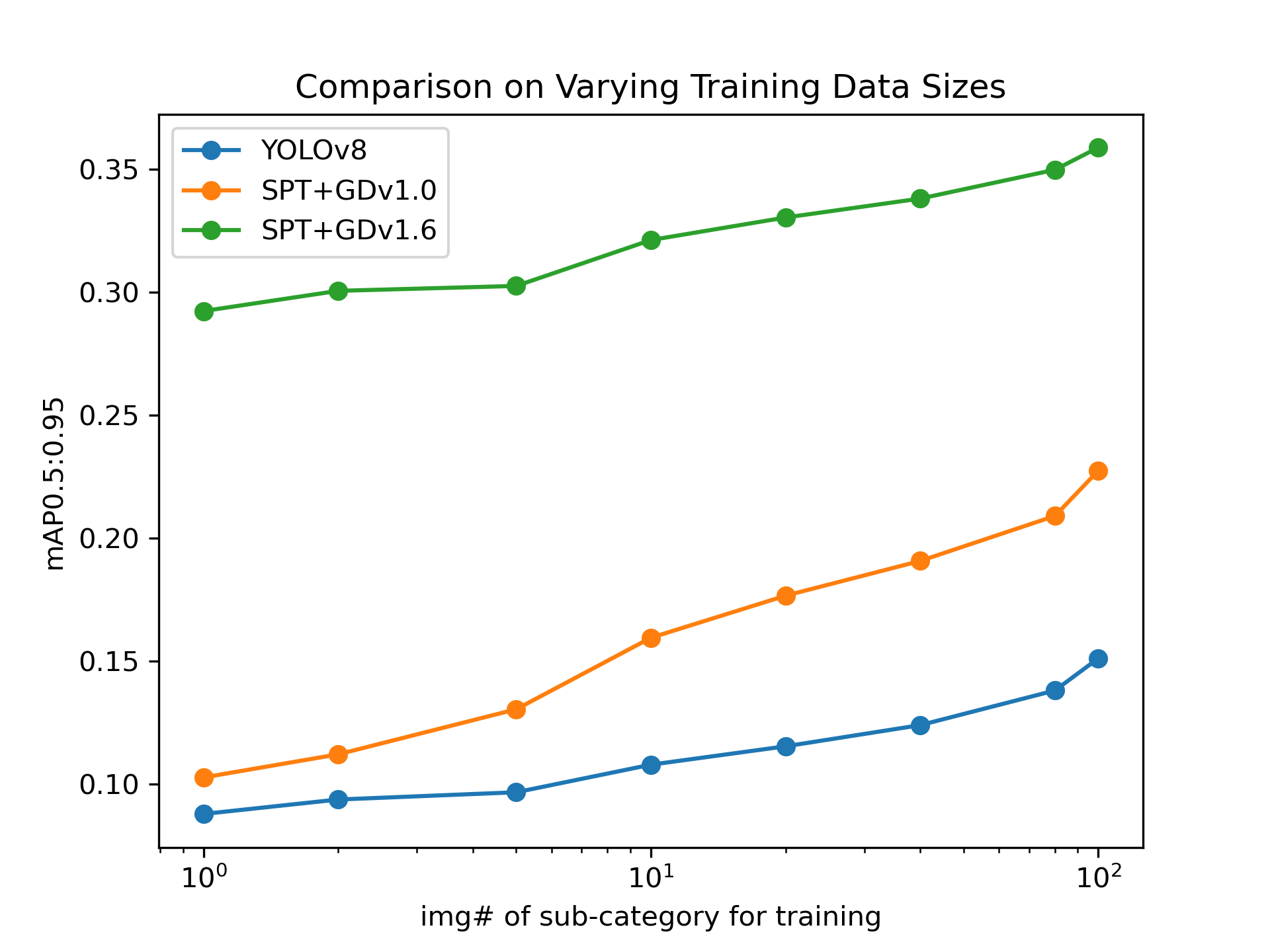
Performance with Varying Training Data Sizes
As shown in Figure 4, the performance with varying training data sizes also demonstrates the strength of SPT. The figure shows that SPT+GD1.6 significantly outperforms SPT+GD1.0, which in turn outperforms YOLOv8. The fewer the training samples, the more pronounced the advantages of SPT.
SPT is a highly effective method that can significantly improve object detection performance, particularly when applied to diverse industry scenarios and handling long-tailed categories with varying amounts of training data. We believe the success of SPT can be attributed to the strong feature fusion and representation capabilities of Grounding DINO, which explains why SPT's performance improves as the Grounding DINO model is upgraded. This allows SPT to serve as a complementary approach to Grounding DINO, and significantly improves its adaptability and accuracy of industrial automation systems, leading to increased productivity, safety, and user experience.
Qualitative Visualization for SPT
This is a scene of a port terminal, where the white objects are special bulk bags each weighing one ton, and the object within the red frame (Figure 5A) is part of crane's horizontal beam. These names are specific terms used in industrial settings, and we detect these two kinds of objects via optimal visual prompts generated by SPT and text prompts.
| Grounding DINO 1.6 Pro with SPT | Grounding DINO 1.6 Pro without SPT |
|---|---|
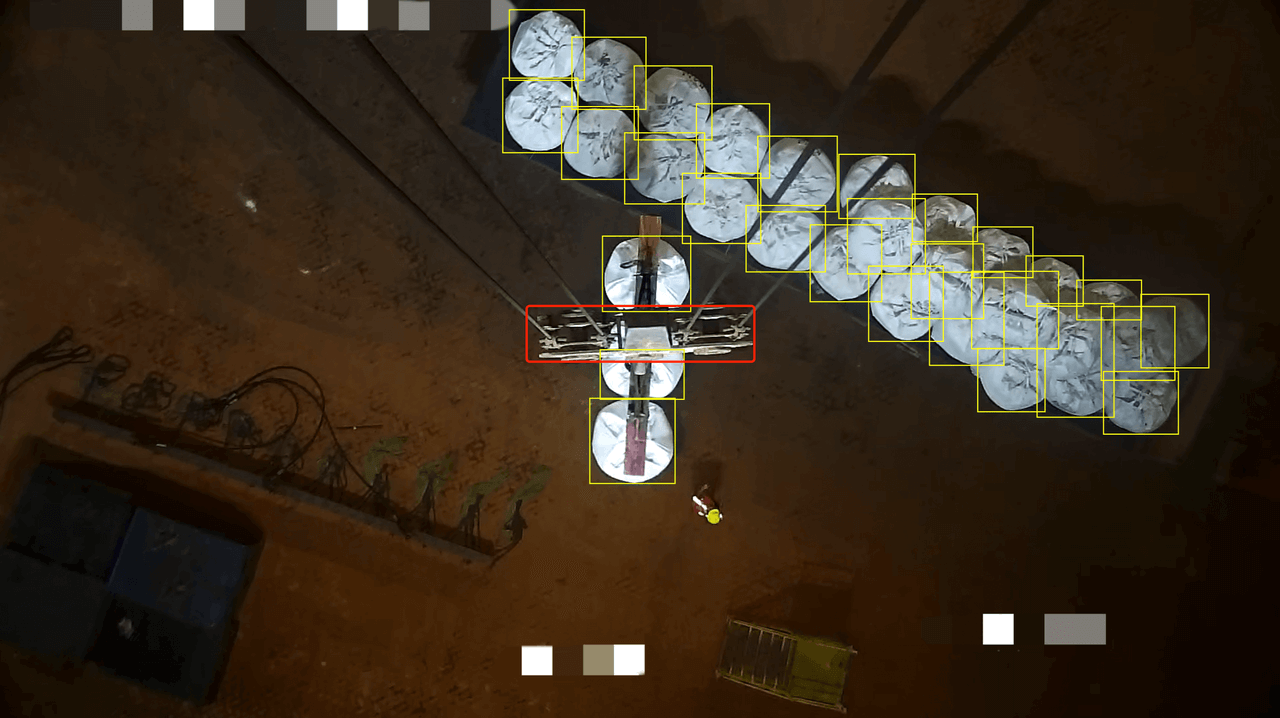 Figure 5A: Detection by Visual Prompt Generated via SPT Using Only 7 Labeled Images |  Figure 5B: Detection by Different Text Prompts |