News
2024-06-24: We have introduced two new free products based on T-Rex2:
CountAnything APP: CountAnything is a versatile, efficient, and cost-effective counting tool that utilizes advanced computer vision algorithms, specifically T-Rex, for automated counting. It is applicable across various industries, including manufacturing, agriculture, and aquaculture.
T-Rex Label: T-Rex Label is an advanced annotation tool powerd by T-Rex2, specifically designed to handle the complexities of various industries and scenarios. It is the ideal choice for those aiming to streamline their workflows and effortlessly create high-quality datasets.
Object detection, the ability to locate and identify objects within an image, is a cornerstone of computer vision, pivotal to applications ranging from autonomous driving to content moderation. A notable limitation of traditional object detection models is their closed-set nature. These models are trained on a predetermined set of categories, confining their ability to recognize only those specific categories. The training process itself is arduous, demanding expert knowledge, extensive datasets, and intricate model tuning to achieve desirable accuracy. Moreover, the introduction of a novel object category, exacerbates these challenges, necessitating the entire process to be repeated.
Against this backdrop, we introduce T-Rex2, a paradigm shift in object detection technology. T-Rex2 is capable of recognizing objects from the everyday to the esoteric, without the need for task-specific tuning or extensive training datasets. This model leverages a novel approach that combines the strengths of text and visual prompts, enabling it to understand and detect a wide array of objects across various scenarios.
Text-Visual Prompt Synergy
In open-set object detection, a prevalent approach is to use text prompts for open-vocabulary object detection. While using text prompts has been predominantly favored, it still faces the following limitations.
1. Long-tailed data shortage. The training of text prompts necessitates modality alignment between visual representations, however, the scarcity of data for long-tailed objects may impair the learning efficiency.
2. Descriptive limitations. Text prompts also fall short of accurately depicting objects that are hard to describe in language.
Conversely, visual prompts provide a more intuitive and direct method to represent objects by providing visual examples. For example, users can use points or boxes to mark the object for detection, even if they do not know what the object is. Nonetheless, visual prompts also exhibit limitations, as they are less effective at capturing the general concept of objects compared to text prompts.
T-Rex2 addresses these limitations by integrating both text and visual prompts in one model, thereby harnessing the strengths of both modalities. The synergy of text and visual prompts equips T-Rex2 with robust zero-shot capabilities, making it a versatile tool in the ever-changing landscape of object detection.
Here is a short video to show the basic capabilities of T-Rex2:
Model Overview
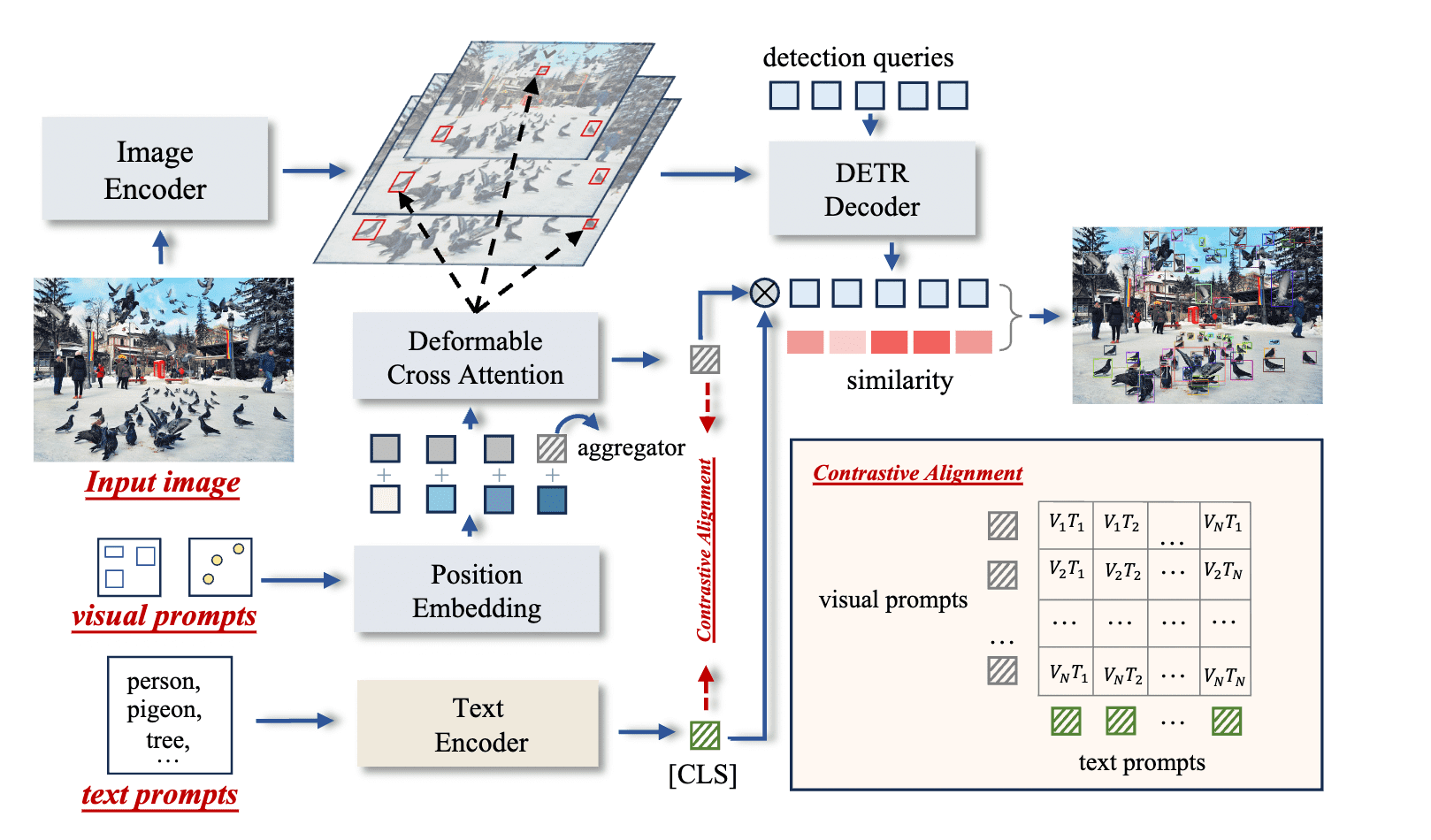
T-Rex2 integrates four components, including: i) Image Encoder, ii) Visual Prompt Encoder, iii) Text Prompt Encoder, and iv) Box Decoder. T-Rex2 adheres to the design principles of DETR which is an end-to-end object detection model. These four components collectively facilitate four distinct workflows that encompass a broad range of application scenarios. We refer readers to our paper for detailed technical insights.
State-of-the-art Performance
T-Rex2 achieves SOTA performance on four academic benchmarks: COCO, LVIS, ODinW, and Roboflow100, all under zero-shot setting.

As shown in above table, we observe that text prompt and visual prompt can cover different scenarios respectively. Text prompt demonstrates superior performance in scenarios with relatively common categories. Conversely, in scenarios characterized by long-tailed distributions, visual prompts exhibit a more robust performance compared to text prompts.
Potential Application Scenarios
T-Rex2 is well-suited for a variety of real-world applications, including but not limited to: agriculture, industry, livstock and wild animals monitoring, biology, medicine, OCR, retail, electronics, transportation, logistics, and more. The flexibility and adaptability of T-Rex2 make it an invaluable tool for researchers, developers, and organizations seeking to push the boundaries of object detection.
T-Rex2 can also be used for open-set video object detection. Given a video, we can extract any N frames, customize a generic visual embedding for a certain object by using T-Rex2's generic visual prompt workflow, and then use this embedding to detect all frames in the video. We show an example of T-Rex2 applied to some videos.
T-Rex2 can also be used for video object tracking. By combining it with the ByteTrack algorithm, T-Rex2 can accurately track any object in a video.
What's Next
Our ambition with T-Rex2 is to equip developers and researchers with a tool that simplifies the complexity of object detection. We aim to foster innovation and invite collaboration across diverse fields, experiencing the capabilities of T-Rex2 through our Demo and API, and exploring the potential applications in your domain. Looking ahead, we envision T-Rex2 playing a pivotal role in a wide spectrum of applications. From enhancing augmented reality experiences to supporting scientific research. We are particularly excited about its ability to serve as a building block for more comprehensive AI systems that can understand and interact with the world in more nuanced and meaningful ways.
We are now opening free API access to T-Rex2. For educators, students, and researchers, we offer an API with extensive usage times to support your educational and research endeavors. Please send a request to this email address (deepdataspace_dm@idea.edu.cn) and attach your usage purpose as well as your institution.
Authors
Acknowledgements
We'd like to thank everyone involved in the T-Rex2 project, including project lead Lei Zhang, application lead Wei Liu, product manager Qin Liu and Xiaohui Wang, front-end developers Yuanhao Zhu, Ce Feng, and Jiongrong Fan, back-end developers Weiqiang Hu and Zhiqiang Li, UX designer Xinyi Ruan, and tester Yinuo Chen.