The video includes Grounding DINO and Grounded-SAM.
Grounding DINO is a strong open-set object detection model, which can be used to DETECT ANY THING with text prompt. This is a fundamental task in computer vision and has wide applications in practice. It not only offers a remarkable capability of novel concept understanding, but also enables many new applications after combining with a series of vision models such as Segment Anything Model and Stable Diffusion. 
Highlight
- Open-Set Detection. Detect anything with text prompt!
- High Performance. COCO zero-shot 52.5 AP (training without COCO data!). COCO fine-tune 63.0 AP.
- Flexible. Combination with Segment Anything Model (SAM) and Stable Diffusion for language-guided Image Segmentation and Editing.
Model Overview
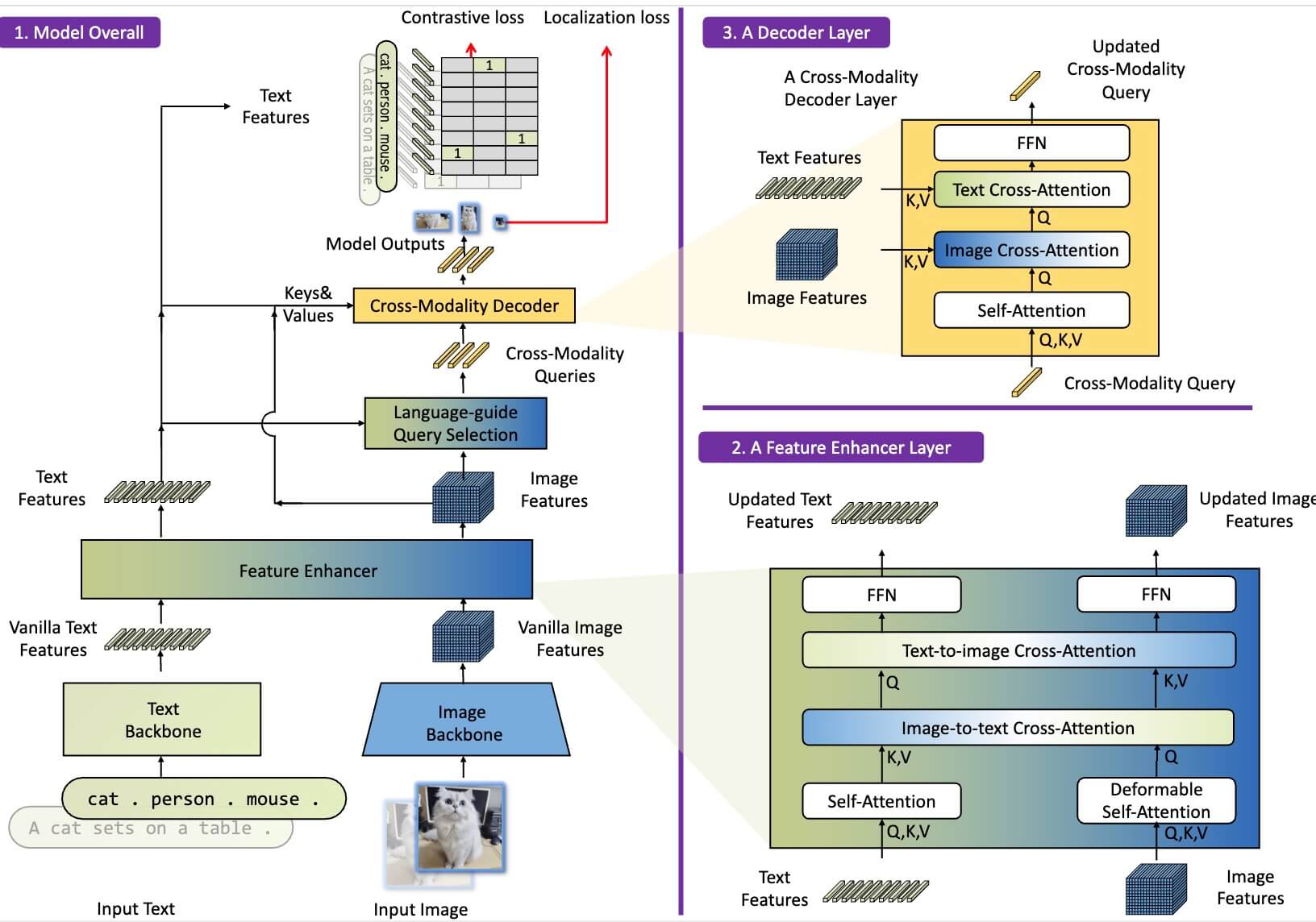
Grounding DINO is a dual-encoder-single-decoder architecture. It contains an image backbone for image feature extraction, a text backbone for text feature extraction, a feature enhancer for image and text feature fusion, a language-guided query selection module for query initialization, and a cross-modality decoder for box refinement. For each "(Image, Text)" pair, we first extract vanilla image features and vanilla text features using an image backbone and a text backbone, respectively. The two vanilla features are fed into a feature enhancer module for cross-modality feature fusion. After obtaining cross-modality text and image features, we use a language-guided query selection module to select cross-modality queries from image features. Like the object queries in most DETR-like models, these cross-modality queries will be fed into a cross-modality decoder to probe desired features from the two modal features and update themselves. The output queries of the last decoder layer will be used to predict object boxes and extract corresponding phrases.
Performance
COCO Results: zeroshot 52.5 AP

ODinW Results

Grounded-SAM: Marry Grounding DINO with SAM
Grounded-SAM: To enable more applications, we further developed Grounded SAM, which combines Grounding DINO with the Segment Anything Model for an unparalleled open-set segmentation capability. Based on this core capability, more vision models such as Stable Diffusion & Recognize Anything can be easily integrated to Automatically Detect, Segment, and Generate Anything. Project: https://github.com/IDEA-Research/Grounded-Segment-Anything 
Links
Arxiv: https://arxiv.org/abs/2303.05499
Code: https://github.com/IDEA-Research/GroundingDINO
Playground: https://deepdataspace.com/playground/grounded_sam
Grounded-SAM: https://github.com/IDEA-Research/Grounded-Segment-Anything
Acknowledgments
We would like to thank everyone involved in the Grounding DINO and Grounded-SAM project, including application lead Wei Liu, product manager Qin Liu and Xiaohui Wang, front-end developers Yuanhao Zhu, Ce Feng, and Jiongrong Fan, back-end developers Weiqiang Hu and Zhiqiang Li, UX designer Xinyi Ruan, and tester Yinuo Chen.