This blog introduces our object detection research work DINO (DETR with Improved deNoising anchOr boxes). DINO achieved the best result on the COCO object detection leaderboard in March 2022 and has kept the leading position until August 2022. It was the first DETR (DEtection TRansformer) type detector that achieves the SOTA performance in object detection, achieving 63.3 AP on COCO. This marked an over tenfold reduction in model parameters and training data compared to previous SOTA detectors!
Paper: https://arxiv.org/abs/2203.03605
Code: https://github.com/IDEACVR/DINO
Main Features:
-
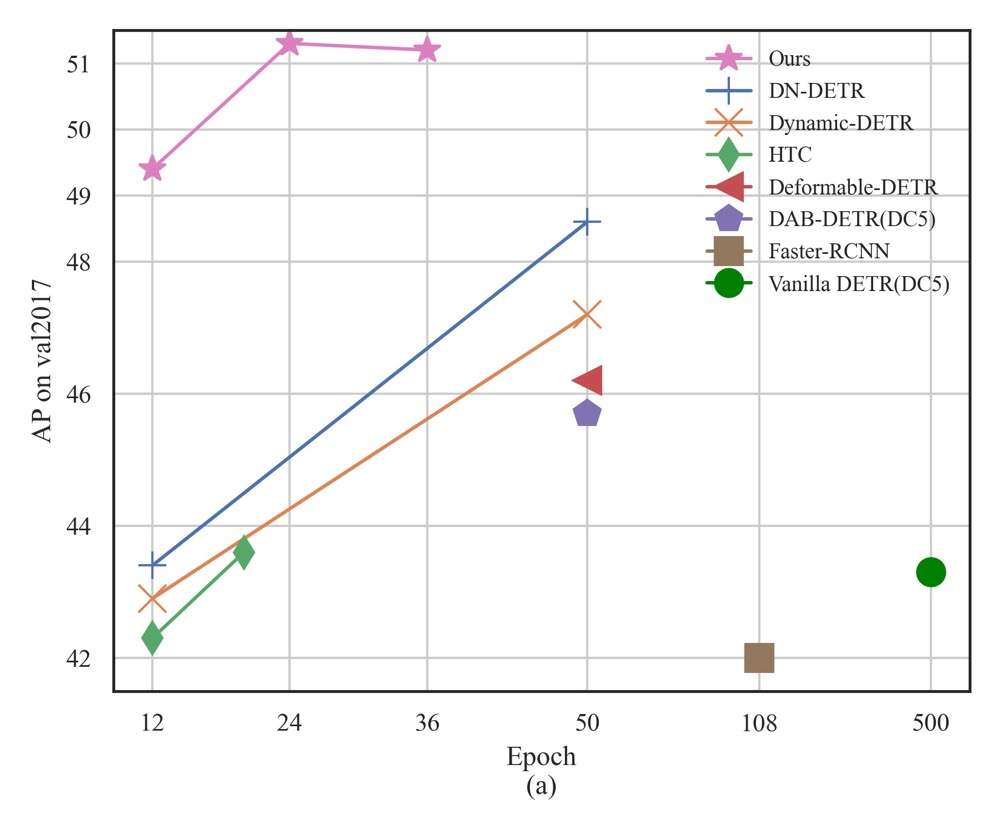
SOTA Performance: Achieves the best detection results with relatively small data and models (about 1/10 compared to previous SwinV2) on large models. It achieves 51.3 AP under the standard ResNet-50 setting.
-
End-to-End Learnable: DINO belongs to the DETR type of detectors, which are end-to-end learnable, avoiding many manually designed modules required by traditional detectors (such as NMS).
-
Fast Convergence speed: In the standard ResNet-50 setting, DINO using a 5-scale feature reaches 49.4 AP in 12 epochs and 51.3 AP in 24 epochs. DINO with a 4-scale feature achieves similar performance and can run at 23 FPS.

Demonstration of Effects


Motivation
Transformers have been widely used in natural language processing and computer vision and achieved the best performance in many mainstream tasks. However, in the field of object detection, the DETR type of detector, which is based on Transformers, although innovative, has not become a mainstream detector widely used before 2022. For example, almost all models on the PaperWithCode leaderboard prior to DINO use traditional CNN detection heads (such as HTC [1]). Therefore, we are very interested in whether DETR, a concise and end-to-end learnable object detector with the added support of a more powerful model Transformer, can achieve better performance? The answer is affirmative.
Background Introduction
Before starting on DINO, several of our lab members have completed the projects DAB-DETR [2] and DN-DETR [3]. DINO is a continuation of these two works, building upon their designs. DAB-DETR addresses the understanding of DETR queries. It explicitly models the DETR's positional query as a four-dimensional box , and in each layer of the decoder, it predicts relative offsets to update the detection box, resulting in a more precise prediction of the detection box . This dynamic update of the detection box aids the decoder's cross-attention in extracting features. DN-DETR explores the bipartite graph matching problem, or label assignment issue, in DETR. We noticed that bipartite matching in DETR is quite unstable in the early stages, leading to inconsistent optimization targets and slow convergence. Thus, we introduced a denoising task which feeds noisy ground-truth boxes into the decoder as a shortcut for learning relative offsets, bypassing the matching process (detailed understanding in our previous article). These two papers deepened our understanding of DETR, making the performance of DETR-like models comparable to traditional CNN models in terms of convergence speed and outcomes. To further improve detector performance and convergence speed, we considered further along the lines of DAB and DN:
-
DAB made us realize the importance of queries. So how can we learn or initialize better queries?
-
DN introduced denoising training to stabilize label assignment. So how can we further optimize label assignment?
Method Introduction

To address the issues mentioned above, DINO proposes three improvements to optimize the model, as illustrated in the diagram.
1. Contrastive Denoising (DN)
In the denoising training of DN, only positive samples introduced with noise are used for learning. However, the model needs to learn not only how to regress the positive samples but also how to distinguish negative samples. For example, DINO's decoder uses 900 queries, but a typical image only contains a few objects, meaning that the vast majority are negative samples. We designed a method for the model to identify negative samples, as shown in the image. We have improved DN not only to regress the real boxes but also to identify negative samples. When large noise is added to the real boxes, we consider them as negative samples, and they are supervised in the denoising training not to predict objects. Moreover, these negative samples are located near the real boxes, making them relatively difficult to distinguish, thus helping the model learn to differentiate between positive and negative samples.

2. Mixed Query Selection
In most DETR models, queries are learned from the dataset and are not related to the input image. To better initialize the decoder queries, Deformable DETR [4] proposed using the encoder's dense features to predict categories and boxes, selecting meaningful predictions from these dense predictions to initialize the decoder features. However, this approach was not widely used in subsequent work. We made some improvements and reemphasized its importance. In queries, we are particularly concerned with the position query, i.e., the box. Meanwhile, features selected from encoder features as content queries for detection are not the best because they are coarse, unoptimized, and might be ambiguous. For instance, for the "person" category, the selected features might only include parts of a person or objects around a person, which are not accurate because they are grid features. Therefore, we improved this by allowing query selection to only choose position queries, utilizing learnable content queries.
3. Look Forward Twice
This method optimizes gradient propagation in the decoder. For more details, please refer to our paper.
Summary
We hope DINO can offer some insights with its state-of-the-art (SOTA) performance, straightforward end-to-end optimization, and fast convergence training, and inference speeds. We also hope that DETR-type detectors gain wider use, highlighting that DETR-type detectors are not only a novel method but also possess robust performance.
References
- HTC https://arxiv.org/abs/1901.07518
- DAB-DETR https://arxiv.org/abs/2201.12329
- DN-DETR https://arxiv.org/pdf/2203.01305.pdf
- Deformable DETR https://arxiv.org/abs/2010.04159